Actually Archiving Your Entire Twitter Account
Most social networks give you the option of downloading an archive of all data stored in your account. If you live in the European Union, my understanding is that these services are now required to give you access to this data, thanks in part to GDPR. However, the quality of archives varies from service to service.
Your Twitter Archive
Twitter makes it easy to download an archive of your data. After following four steps, a link to your archive will arrive in your inbox. The ZIP file includes an HTML view of your timeline as well as access to your tweets in CSV format.
Many services allow you to download a human-browsable archive and a machine-readable archive. This commonly looks like a static HTML site for humans and a set of JSON files for machines. Twitter includes both in its archive, but the included data is laughably incomplete.
To me, my Twitter account includes all of the following data:
- My tweets, including photos, videos, polls, etc.
- My favorites
- My public and private lists
- The accounts I follow
- The accounts that follow me
- My direct messages
Of the above, Twitter's account archive only includes partial Tweet data. That's it! No favorites, no lists, no direct messages. The most surprising thing to me was that Twitter does not give you a copy of any of the photos or videos posted to your account. Instead, that data continues to live on Twitter's servers.
When viewing your archive without an internet connection, avatars and images disappear. I guess Twitter hopes you didn't really want to save any of those photos after all.
The Twitter archive does include a tweets.csv file with all of your accounts tweets. However, this format losses much of the information returned via the Twitter API. The documentation details the rich information on each tweet that the archive throws away. Why not use the schema already in use by the API? I'm not sure why Twitter thought a CSV would be an easier format to consume.
Building a Better Archive
Unhappy with my archive, I set out to build one that meets my needs. Using a combination of the Twitter API and official archive, I'm able to create a new archive that contains everything I've done on Twitter. It's called Grain and you can use it today. Your Grain archive includes the following records:
- Direct messages
- Favorites
- Followers
- Friends
- Lists
- Tweets
Most importantly, the archive includes all images associated with the above records. For comparison, here's the data in my official archive versus the archive built via Grain.
| Records | Grain | |
|---|---|---|
| tweets | 4,348 | 4,348 |
| favorites | 2,281 | |
| friends | 105 | |
| followers | 640 | |
| direct messages | 9 | |
| lists | 3 | |
| images | 1,986 |
The records are stored as JSON, backed by protocol buffers. I'm hoping this makes it easy to build other tools that interact with your archive.
Tweets are stored as the full object returned from the Twitter API, which includes far more information than contained in the official archive. Highlights include a fully hydrated user object and detailed display information.
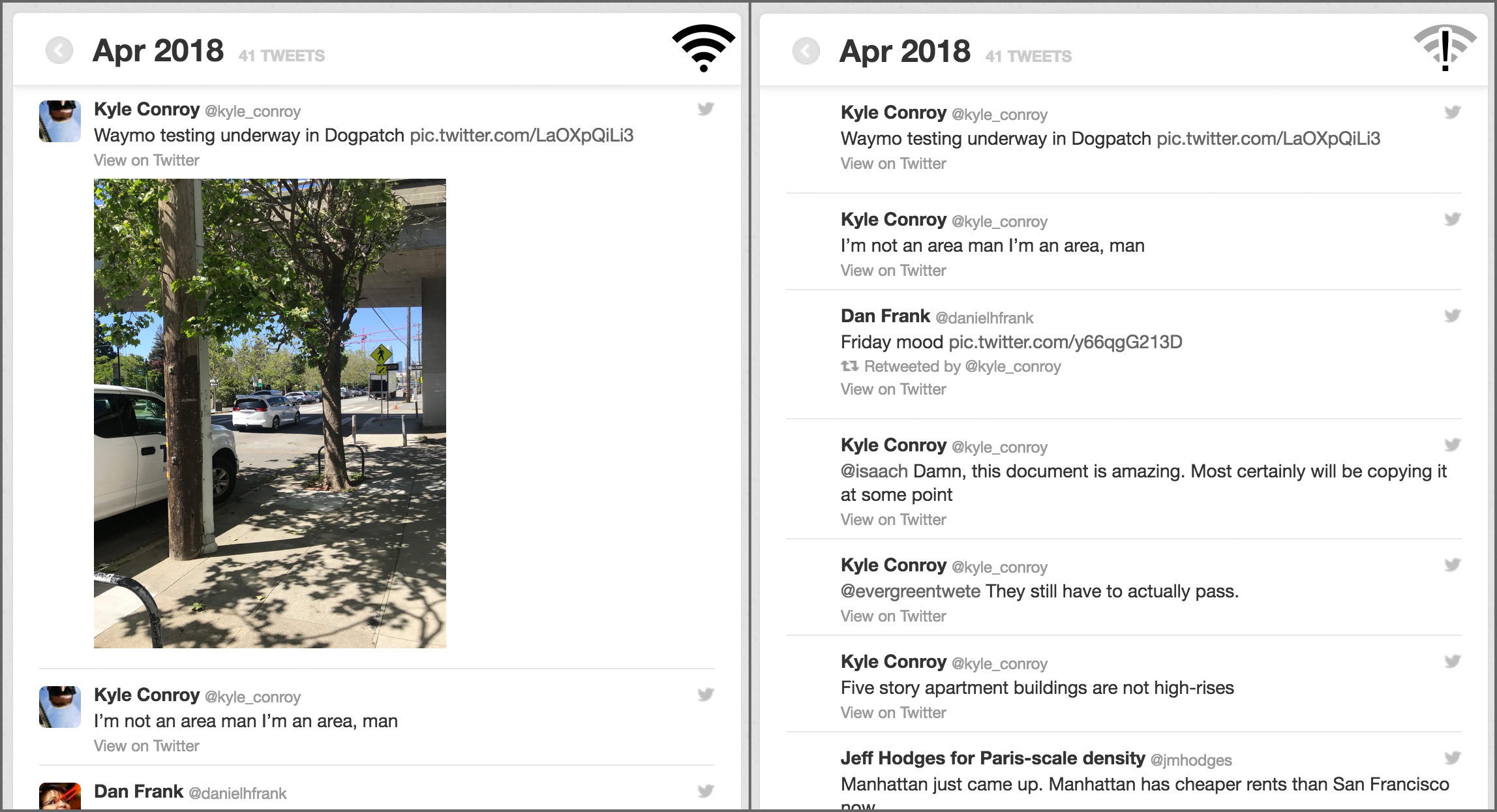
A few months ago I tweeted about Waymo testing their self-driving cars in my neighborhood.
Waymo testing underway in Dogpatch pic.twitter.com/LaOXpQiLi3
— Kyle Conroy (@kyle_conroy) April 21, 2018
Here's the data for that tweet from the official archive (CSV converted to YAML for readability):
tweet_id: 987812599591878656 in_reply_to_status_id: in_reply_to_user_id: timestamp: 2018-04-21 21:57:31 +0000 source: <a href="http://tapbots.com/tweetbot" rel="nofollow">Tweetbot for iΟS</a> text: Waymo testing underway in Dogpatch https://t.co/LaOXpQiLi3 retweeted_status_id: retweeted_status_user_id: retweeted_status_timestamp: expanded_urls: https://twitter.com/kyle_conroy/status/987812599591878656/photo/1
And the same tweet in the Grain archive:
{
"created_at": "Sat Apr 21 21:57:31 +0000 2018",
"display_text_range": [
0,
34
],
"entities": {
"hashtags": [],
"media": [
{
"display_url": "pic.twitter.com/LaOXpQiLi3",
"expanded_url": "https://twitter.com/kyle_conroy/status/987812599591878656/photo/1",
"id": "987812583188017152",
"indices": [
"35",
"58"
],
"media_url": "http://pbs.twimg.com/media/DbVqT42VMAAK4r3.jpg",
"media_url_https": "https://pbs.twimg.com/media/DbVqT42VMAAK4r3.jpg",
"sizes": {
"large": {
"h": 1024,
"resize": "fit",
"w": 768
},
"medium": {
"h": 1024,
"resize": "fit",
"w": 768
},
"small": {
"h": 680,
"resize": "fit",
"w": 510
},
"thumb": {
"h": 150,
"resize": "crop",
"w": 150
}
},
"type": "photo",
"url": "https://t.co/LaOXpQiLi3"
}
],
"urls": [],
"user_mentions": []
},
"extended_entities": {
"media": [
{
"display_url": "pic.twitter.com/LaOXpQiLi3",
"expanded_url": "https://twitter.com/kyle_conroy/status/987812599591878656/photo/1",
"id": "987812583188017152",
"indices": [
"35",
"58"
],
"media_url": "http://pbs.twimg.com/media/DbVqT42VMAAK4r3.jpg",
"media_url_https": "https://pbs.twimg.com/media/DbVqT42VMAAK4r3.jpg",
"sizes": {
"large": {
"h": 1024,
"resize": "fit",
"w": 768
},
"medium": {
"h": 1024,
"resize": "fit",
"w": 768
},
"small": {
"h": 680,
"resize": "fit",
"w": 510
},
"thumb": {
"h": 150,
"resize": "crop",
"w": 150
}
},
"type": "photo",
"url": "https://t.co/LaOXpQiLi3"
}
]
},
"full_text": "Waymo testing underway in Dogpatch https://t.co/LaOXpQiLi3",
"id": "987812599591878657",
"lang": "en",
"source": "<a href=\"http://tapbots.com/tweetbot\" rel=\"nofollow\">Tweetbot for i\u039fS</a>",
"user": {
"created_at": "Sun Jun 27 16:44:20 +0000 2010",
"description": "Currently increasing GDP of the internet at @stripe. Formerly StackMachine, Twilio and UC Berkeley.",
"entities": {
"url": {}
},
"favourites_count": "2298",
"followers_count": "646",
"friends_count": "105",
"id": "160248151",
"lang": "en",
"listed_count": "28",
"name": "Kyle Conroy",
"profile_background_color": "131516",
"profile_background_image_url": "http://abs.twimg.com/images/themes/theme14/bg.gif",
"profile_background_image_url_https": "https://abs.twimg.com/images/themes/theme14/bg.gif",
"profile_background_tile": true,
"profile_banner_url": "https://pbs.twimg.com/profile_banners/160248151/1441003908",
"profile_image_url": "http://pbs.twimg.com/profile_images/691734524355424256/Jsa2rYyB_normal.jpg",
"profile_image_url_https": "https://pbs.twimg.com/profile_images/691734524355424256/Jsa2rYyB_normal.jpg",
"profile_link_color": "009999",
"profile_sidebar_border_color": "EEEEEE",
"profile_sidebar_fill_color": "EFEFEF",
"profile_text_color": "333333",
"profile_use_background_image": true,
"screen_name": "kyle_conroy",
"statuses_count": "4086",
"url": "https://t.co/qOYJRRAPQu"
}
}
Sadly, it's not a perfect tool due to the limitations of the Twitter API. Direct messages older than 30 days are not available in the API. Without access to the official archive, the tool can only retrieve and store that last 2,300 tweets from your account. I have no idea why Twitter picked such a arbitrary limit.
The archive is also missing some data. I haven't figured out how to archive videos, moments, polls, or saved searches.
I'm hoping that my work will convince Twitter to improve its own archive and make Grain obsolete. If you feel like Twitter should provide you all your data without jumping through hoops, send a message to @TwitterSupport. If you work or worked at Twitter, please reach out if you can put me in contact with the team that owns account archives. I'd love to give them my feedback directly.